
MQ消息中间件学习笔记
MQ消息中间件学习笔记
三个问题
- 消息队列适合什么场景?
- 消息队列有哪些主流产品、各自的优缺点?
- 消息队列背后的设计思想(整体核心模型、数据存储考量、数据获取方案对比、消费者消费模型)
消息队列适合场景
- 异步处理数据:快递员与收货用户
- 系统应用解耦:公用资源库与上游应用
- 业务流量削峰:电商秒杀
适用于消息不需要实时处理、一份数据多处使用(不同消费方消费速度不同)的场景
*主流消息中间件及对比
ActiveMQ: 基于 Java 语言开发的一个开源的消息代理。支持多个客户机、服务器、计算机集群等。
RabbitMQ:实现了高级消息队列协议(AMQP)。用 Erlang 编写构建在开放电信平台框架上。所有主要的编程语言均有与代理接口通讯的客户端库。支持多种消息传递协议、传递确认等特性。
Kafka: 由 Scala 写成。一个分布式的、分区的、多复本的日志提交服务。它通过一种独一无二的设计提供了一个消息系统的功能。
RocketMQ: 一个分布式消息和流媒体平台,具有低延迟、强一致、高性能和可靠性、万亿级容量和灵活的可扩展性。
Pulsar:下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案。
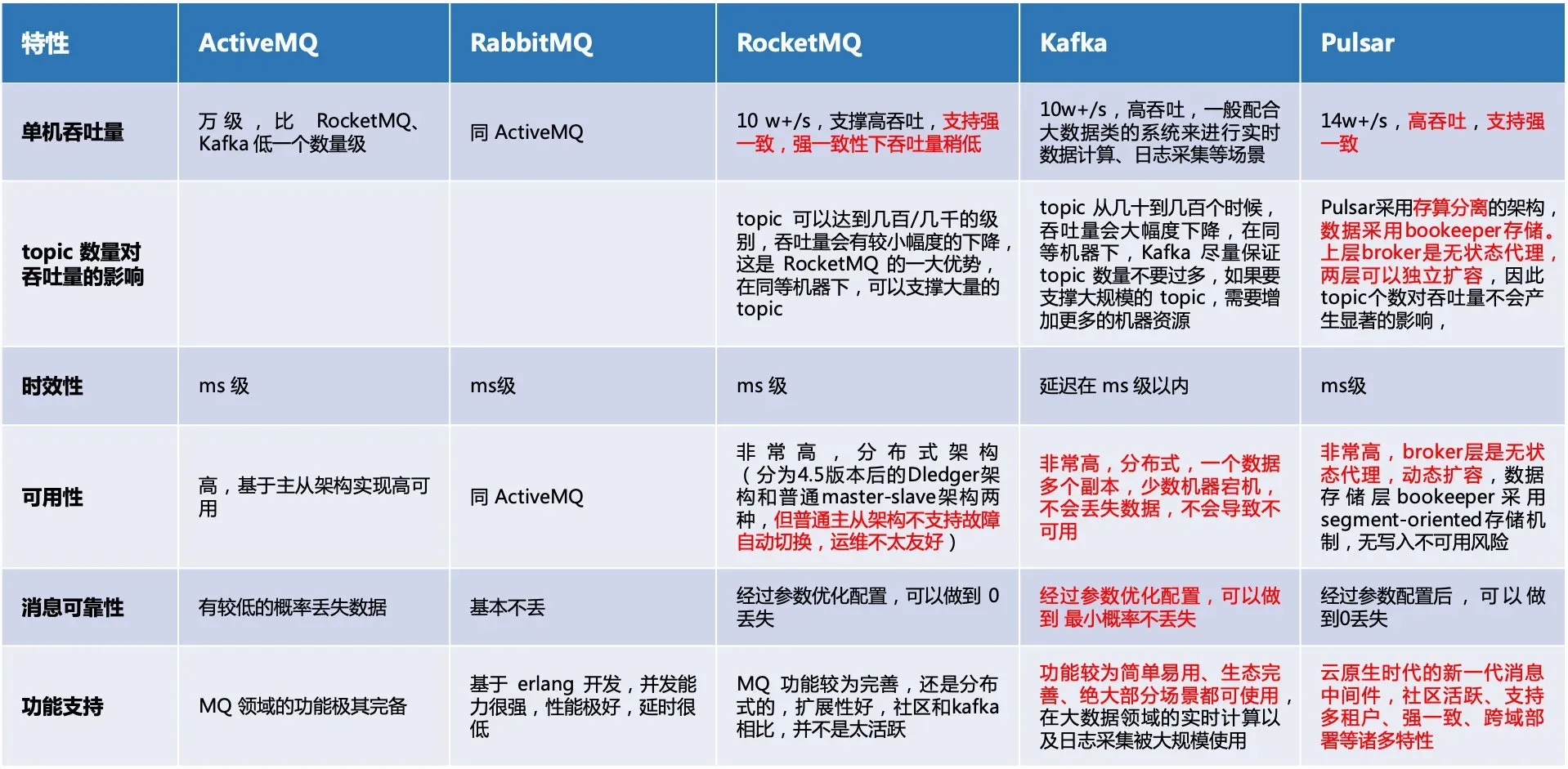
支持强一致性的有 RocketMQ 和 Pulsar。kafka 有数据丢失的风险,吞吐量比较高且社区活跃,可应用在大部份场景;kafka、RocketMQ、Pulsar 是基于磁盘存储数据的,内存加速访问。而 ActiveMQ、RabbitMQ 采用内存存储数据,也支持数据持久化到磁盘。
消息中间件设计思想
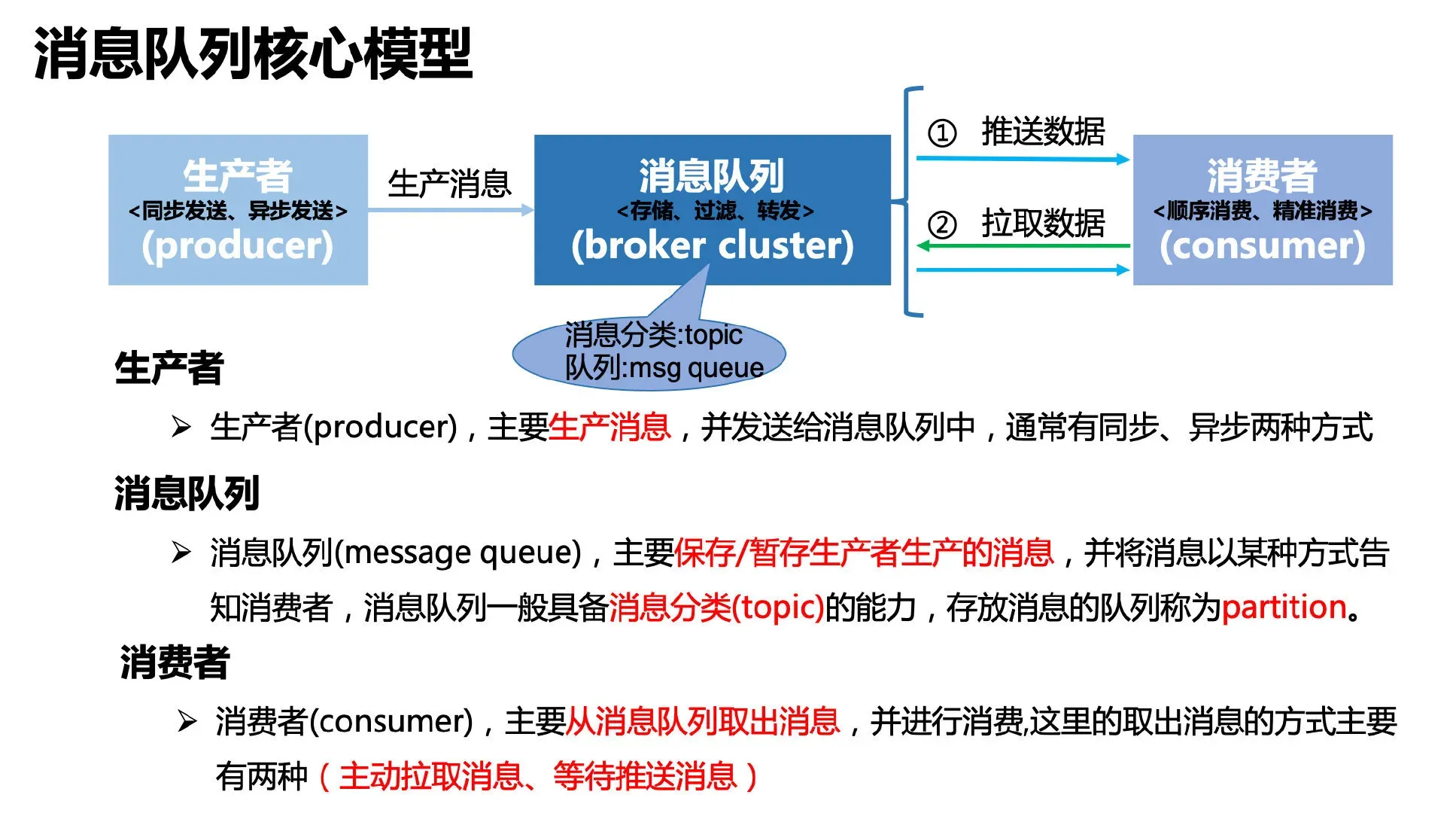
消费者从消息队列中获取数据时,主要有两种方案:
-
等待推送数据:消息实时性强、对消费者资源无法充分利用、消息队列内部实现相对容易、对推送失败或消费速度较慢点消息进行缓冲重试(RabbitMQ、ActiveMQ)
-
主动拉取数据:消息实时性弱、更好适配不同类型的消费者、需要消费者告知目前的消费位置、需要消费者与队列之间建立长轮询(Kafka、RocketMQ、RabbitMQ、ActiveMQ)
消息队列消费模型
消费者消费者模型其实是一个 1:N:M 的关系,一份数据被 N 个消费者组独立使用,每个消费者组中有 M 个消费者进行分摊消费
这种模型也叫发布订阅模型,对于一条消息而言,组间广播,组内单播。组内也有负载均衡:轮询、随机、hash、一致性hash。
AMQP(Advanced Message Queuing Protocol)
AMQP设计目标:让服务端可以通过协议编程,是一个二进制协议,具有多通道、可协商、异步、安全、便携、语言中立、高效的特性。分为两层:
- 功能层:定义了一系列命令
- 传输层:携带了从应用 -> 服务端的方法。
分层可以单独替换某一层而不会影响另一层




